Designing a Linear Broadcast Scheduling Interface for NBCUniversal
By Domenic DiNatale
A linear broadcast scheduling interface looks, from a distance, like a calendar with extra columns. That is exactly what it is — and why most software people underestimate it. The constraints around what can go in the calendar, when it can change, who can change it, and what happens if the calendar is wrong at the moment a feed goes on-air are the actual product. We built one of these for NBCUniversal and Versant — a unified, cloud-native platform that manages the scheduling, translation, and distribution of 20+ linear television feeds across time zones — and the architecture decisions that mattered are not the obvious ones.
This is what we learned.
What "Linear" Actually Means
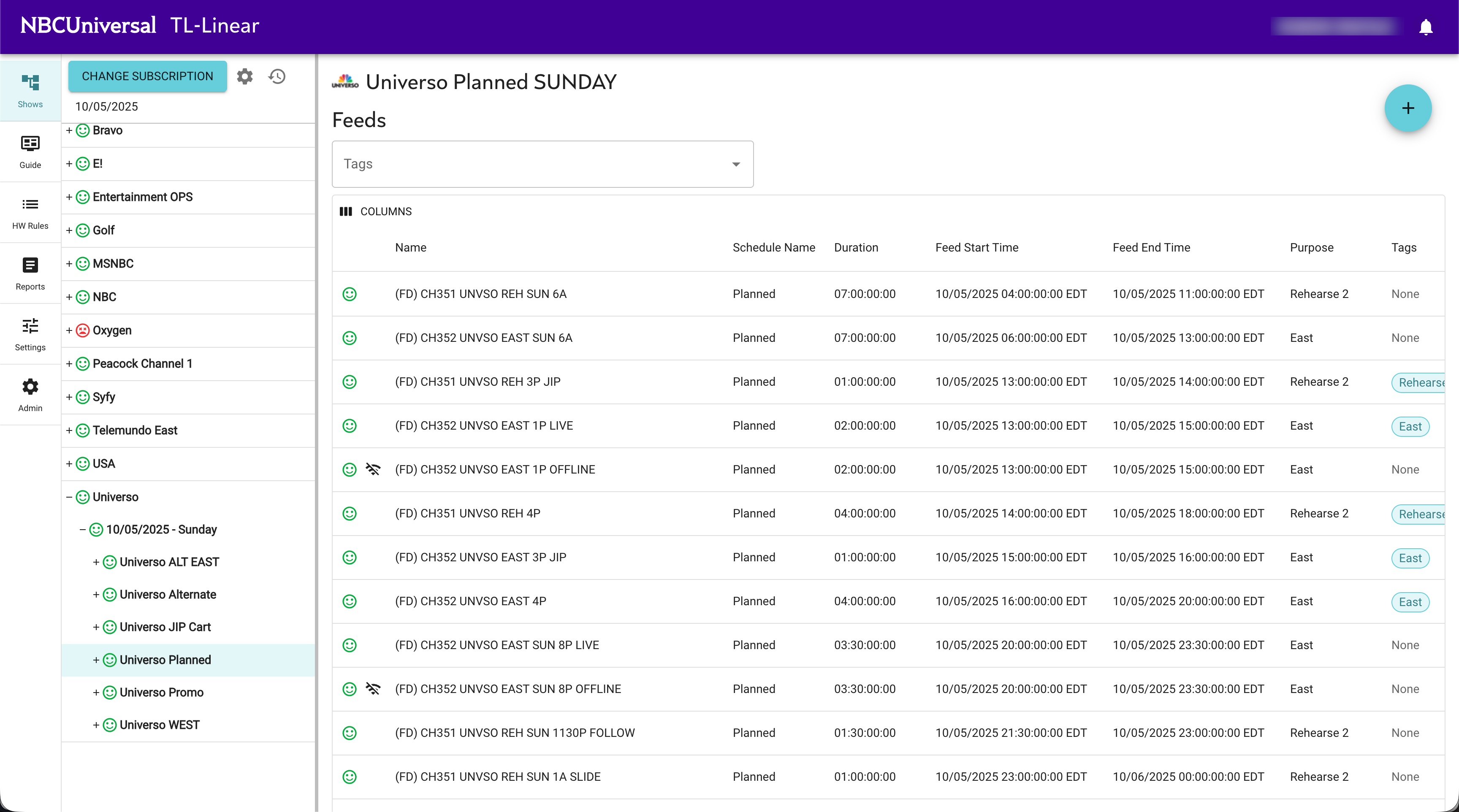
In broadcast, linear refers to a continuous, programmed channel feed — the kind of television where if you tune in at 8:00 PM, something is on, whether or not anyone is watching. The opposite is on-demand: you press a button, you get a thing. Linear is harder than on-demand for a reason that takes a moment to internalize: the schedule has to be correct at the moment of broadcast, in every relevant time zone, across every feed variant, with every contractual and regulatory constraint upheld. There is no graceful degradation. If the system gets it wrong, the wrong thing airs. If it can't get an answer fast enough, dead air goes out.
The interface that lets a scheduler manage this is doing more than CRUD. It is presenting a deeply structured plan, tracking dependencies between feeds (a Spanish-language version of a flagship channel cannot drift independently of its source), reasoning about time-zone offsets in a domain where DST transitions are an actual operational hazard, and giving the human in the chair a fast, reliable way to make changes that propagate correctly. The constraints are the product.
The Architecture, Briefly
Translator Linear runs on a stack we chose for specific reasons:
- A modern, strongly-typed reactive frontend framework for the UI, because a scheduling grid where every cell needs to react to changes elsewhere on the grid demands fine-grained reactive state, and because the type system is doing real work — in a domain with twenty entity types and dozens of subtle relationships, untyped JavaScript would be a liability.
- GraphQL as the API layer, because the frontend's data needs vary dramatically per view (timeline, grid, conflict-resolver, settings) and because the alternative — REST endpoints sized to each view — fragments the API surface in ways that hurt operational reliability.
- A reactive, event-driven JVM framework for the backend microservices, because broadcast scheduling is event-driven (a feed update propagates to dependent feeds; a contractual constraint is checked against a schedule change; an audit event is emitted for regulatory traceability), and a reactive event model fits that shape natively without our having to fight a request/response framework into doing it.
- A document-oriented (non-relational) database for the data layer, because schedule documents are deeply nested, frequently queried by time-window-and-feed slices, and almost never updated in the relational-DB sense — the access patterns favor a document store.
- Kubernetes for container orchestration, because scheduling activity is spiky (the early-evening replan window and late-night autopilot are different workloads with different scaling needs), and because Kubernetes' rolling-deploy primitives are the foundation for the zero-downtime story we care most about.
None of those are surprising choices in 2026. The decisions that mattered were how we wired them together.
Why GraphQL Was the Right Call
Most teams reach for GraphQL because they like the developer experience. That's a fine reason. We reached for it because of a specific operational property: a scheduling UI has views that need overlapping but distinct slices of the same underlying data, and the cost of getting that wrong with REST is paid at the worst possible moment.
If the timeline view needs feeds plus their schedule entries plus their downstream dependents plus the resolved conflict count for a given window, and the grid view needs the same feeds plus their permission scope plus their per-feed audit summary, you can either build two REST endpoints that diverge over time as both views evolve (and discover, six months in, that one is missing a field the UI silently depends on), or you let the client describe its data needs and have the server resolve them through a single typed schema. The second pattern is more discipline up-front and less drift over time. In a system where drift between API and UI shows up as a scheduling bug at 8:00 PM on a Sunday, less drift is the right answer.
Why an Event-Driven Backend
A reactive, event-driven framework is a less obvious choice in a JVM landscape dominated by traditional request/response frameworks. We picked one because the scheduling domain is a chain of small, asynchronous reactions, and an event-bus model is the cleanest expression of that pattern we've worked with. A schedule change publishes an event; downstream services react — dependency resolution, conflict checking, audit emission, downstream-feed propagation — without the change propagation being baked into the calling service's request handler.
This is structurally important. In the alternative architecture, where the scheduling service synchronously calls every dependent service in its update path, a single slow downstream becomes a slow scheduler, which becomes a UI that hangs, which becomes a scheduler hitting refresh during the live window, which is the failure mode you most want to avoid. Decoupling the change publication from the change consumption removes that coupling at the architectural level, not as an after-the-fact retry layer.
The Operational Discipline That Doesn't Show on the Diagram
Platform-wide governance shows up in places that don't appear in the architecture diagram. Service repositories share common base images so that a security or supply-chain fix lands once and propagates everywhere. Branch protection, required reviewers, and code-quality gates are applied uniformly through automation rather than per-team conventions. Kubernetes deployments use metrics-driven horizontal autoscaling tuned to indicators that correlate with actual scheduler load. CI/CD pipelines are templated so that operational changes propagate consistently across services rather than getting reimplemented per service.
None of that is in the architecture diagram. All of it is the difference between a system that runs reliably and a system that gives someone an incident at 11:00 PM.
The line we hold on this is that operational discipline is not optional infrastructure you add at the end. It is part of the system from day one, expressed as code, version-controlled, reviewed, and applied uniformly. A platform that handles a high-stakes linear broadcast portfolio cannot run on per-team conventions. It runs on automation that makes the right thing the easy thing.
Zero-Downtime as a Design Principle
The thing that distinguishes broadcast software from most software is that downtime is not a degraded experience — it is an on-air failure. The architectural decisions that fall out of that constraint are the most consequential ones we made.
Every service rolls without taking traffic offline; the database access patterns are designed so that schema migrations can run alongside live traffic without breaking either the old version or the new; the GraphQL schema evolves additively, with deprecations rather than removals; the Kubernetes pod disruption budgets are tuned so that cluster activity (node replacements, autoscaling events, version upgrades) cannot drain a service below its operational floor.
These are not exotic patterns. They are what you get when you take "no downtime ever" seriously as a design principle and apply it to every layer of the stack. The discipline of designing every change so it can be deployed live, rolled back live, and evolved live is the operational substrate that lets the rest of the platform run.
What Held Up
Translator Linear has run continuously through the most demanding moments in linear broadcast — high-stakes live event windows, organizational transitions in the broadcast environment, the kind of activity where downtime is not a degraded experience but an on-air failure — and the architecture has held up. The combination of fine-grained reactive frontend, GraphQL data layer, event-driven backend, document-shaped storage, and zero-downtime container orchestration has done what we asked it to do.
If you take one thing away from this: the parts of a linear broadcast scheduling interface that are easy to build are not the parts that determine whether the system gets used. The audit log, the time-zone math, the dependency propagation, the deployment story, the operational automation — those are the parts. We designed for them from the beginning. Three years in, we are glad we did.
Related work from our team:
The project narrative lives on the Translator Linear case study page. For context on how we think about engineering for environments where downtime equals on-air failure, see Human Error Is Predictable. Cascading Failure Is Optional. and The Blast Radius Problem.