
What Even Is an AI Token?
By Domenic DiNatale
If you use AI in your business, you are already paying for tokens. Your API invoice is denominated in them. The model's working memory is bounded by them. The latency of a response is roughly proportional to them. Tokens are the fundamental unit of how these systems consume and produce language — and yet almost no one can tell you what one actually is.
That gap matters more than it sounds. A surprising number of practical decisions — what a feature costs to run, why a long conversation starts losing the thread, why a model that can draft a contract reads your words in a way that has nothing to do with their letters — come straight back to this one concept. Understanding it does not require any mathematics. It requires about five minutes and a willingness to stop thinking in words.
Models Read Tokens, Not Words
The first thing to unlearn is the assumption that a language model reads text the way you do. It does not see letters, and it does not quite see words either. It sees tokens — chunks of text that the model was trained to recognize as units.
A token is sometimes a whole word. Often it is a fragment of one. Common words like "the" or "and" usually get their own token. Longer or less frequent words get broken into familiar pieces. The word "unbelievable," for instance, is not one unit to a model. It is three: un, believ, and able. The model reassembles meaning from those pieces, but it is always operating on the pieces, not on the word you typed.
This is not an arbitrary design choice. Breaking language into sub-word tokens is what lets a model handle a vocabulary of essentially unlimited words — including names, typos, and terms it has never seen — using a fixed, manageable set of building blocks. It is an efficient representation. It is also the source of several behaviors that look strange until you know the unit involved.
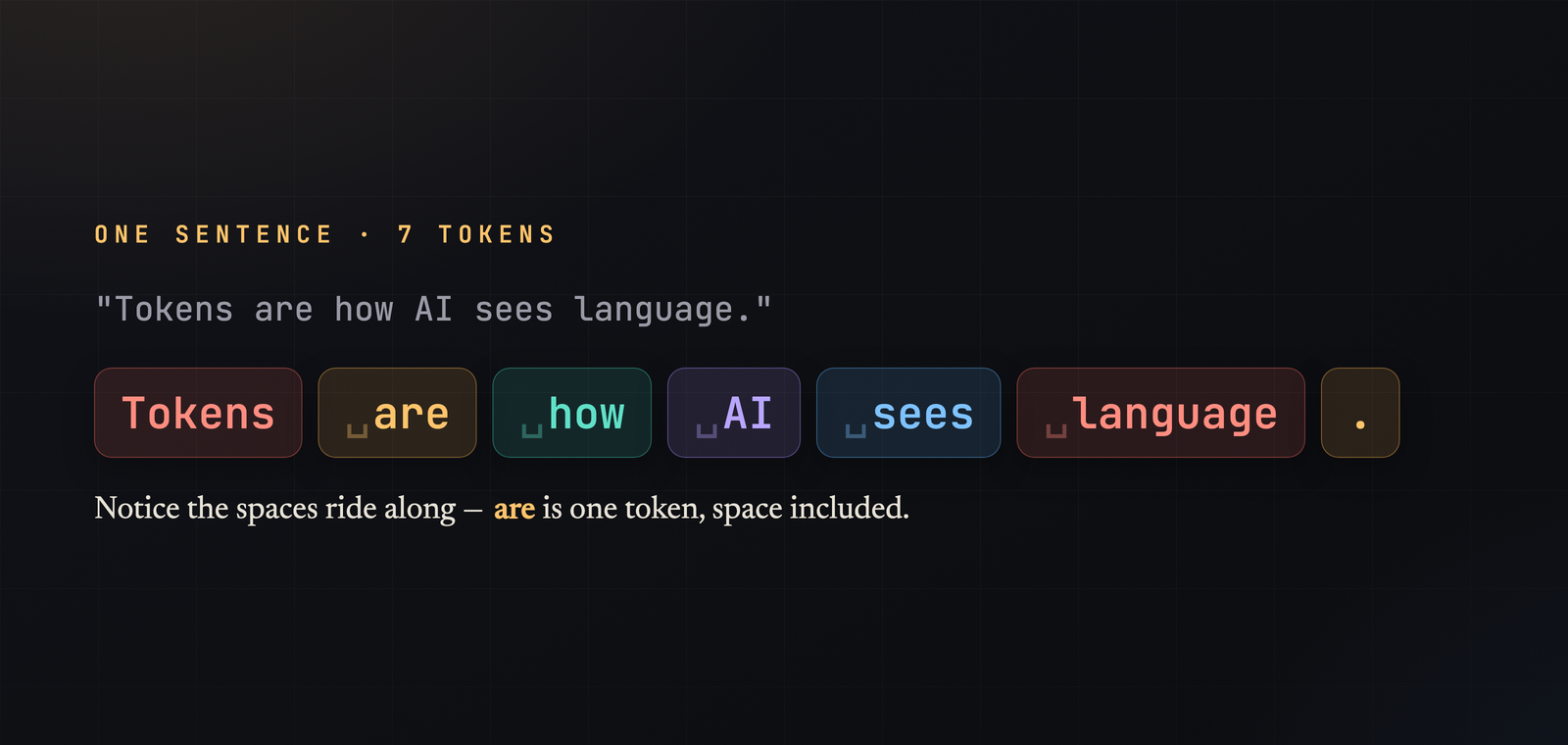
A Sentence, Tokenized
Consider an ordinary sentence: "Tokens are how AI sees language." To you that is six words. To a model it is closer to seven tokens, split something like this:
Tokens · are · how · AI · sees · language · .
Two details are worth noticing. First, the spaces ride along. The token for "are" is actually a space followed by "are" — the leading space is part of the unit. Punctuation, like the period at the end, is typically its own token as well. Every space, comma, and capital letter is part of the count.
Second, the split is not one-token-per-word. Sometimes it happens to line up neatly, as it mostly does here. Often it does not. A common word lands in a single token; an unusual product name or a long technical term might be chopped into four or five. The tokenizer optimizes for frequency, not for the boundaries humans care about.
How Big Is One Token
You do not need to count tokens by hand, and you rarely need precision. One rule of thumb covers almost every practical situation:
Roughly four characters of English text equal one token. One hundred tokens is about seventy-five words.
So a hundred tokens is a short paragraph. A one-page document is somewhere in the range of five to six hundred tokens. A lengthy email thread you paste in as context can easily run into the thousands. That is all the mental model most people ever need, and it is enough to reason about the two things that actually cost you something.
Why It Matters, Part One: Cost
Every commercial AI API prices the same way, regardless of vendor. The bill comes down to two numbers: tokens in and tokens out. Tokens in are everything you send — your prompt, your instructions, and any documents or context you attach. Tokens out are everything the model generates in response.
There is a detail here that catches teams off guard: output tokens are usually priced higher than input tokens, sometimes several times higher. A model that "thinks out loud" with a long, meandering answer can cost more than the question that prompted it. This has direct consequences for how you design anything that runs at scale. A prompt padded with irrelevant context is not just sloppy — it is more expensive on every single call, forever. Tighter prompts and constrained output lengths are not stylistic preferences. They are line items.

Why It Matters, Part Two: The Context Window
The second reason to care is that a model can only hold so many tokens in mind at once. That limit is called the context window, and it functions like the surface of a desk with a fixed area. Your conversation, the documents you have shared, and the model's own previous responses all have to fit on that desk simultaneously. When it fills, the oldest material slides off the back edge to make room.
This is the mechanical reason a long chat eventually seems to "forget" what was established at the start. Nothing has malfunctioned. Those early tokens have simply fallen out of the window. Modern models have very large windows — hundreds of thousands of tokens in some cases — but the principle is unchanged regardless of the size: the window is finite, and it fills. Any system that feeds a model large documents or long histories has to manage that budget deliberately, deciding what stays on the desk and what gets summarized or dropped.

The Strawberry Problem
There is a well-known party trick: ask an AI how many times the letter "R" appears in "strawberry." For a long time, models answered confidently and wrongly, and it became the go-to proof that AI is secretly not very bright. Today most current models get it right — and why they get it right is more instructive than the failure ever was.
The model still does not see the word as ten individual letters. It sees two tokens: straw and berry. Nothing about that changed. What changed is that models learned to compensate — the example became so common that the answer is effectively memorized, and reasoning-capable models now spell the word out step by step to count it deliberately. The blind spot is still there; the model just works around it.
That distinction matters, because the underlying limitation has not gone away. Any task that depends on looking inside a token — counting characters in an unusual string, reversing exact spelling, precise character-level edits — is still where token-based models are weakest. They reason about chunks, not characters. Strawberry got solved; the category of problem did not.

What This Means in Practice
Once tokens click into place, a lot of AI's behavior stops being mysterious and starts being predictable.
Costs scale with tokens in plus tokens out, so trimming prompts and bounding output length is the most direct lever you have on spend. Long sessions lose context because the window filled, so anything that needs to remember a lot needs an explicit strategy for what to keep. And the occasional baffling failure at a "simple" task usually means the task required looking inside a token the model only ever saw whole.
None of this is exotic. It is just the consequence of one fact: when you prompt an AI, you are not speaking in words. You are speaking in tokens. Fewer and sharper tokens generally mean faster, cheaper, and more reliable results — which makes this small piece of literacy one of the better-leveraged things a team can understand about the tools it is already paying for.
Read more on building and operating intelligent systems on the Intellitech blog.