AI Systems Have an Architecture Problem Too
By Domenic DiNatale
In 2023, researchers began documenting a class of attack against large language model applications that they called prompt injection. The attack was straightforward in concept: embed instructions inside data that the AI would process, and those instructions would execute as if they came from a legitimate source. Tell the AI, inside a document or an email or a web page, to ignore its previous instructions, and under the right conditions it would.
The response from the development community followed a predictable path. New prompt engineering techniques emerged. System prompts were hardened. Filters were added. Defenses were proposed at the level of the prompt itself.
The attacks kept working.
This should be familiar. We've seen this pattern before — in phishing, in authentication, in every case where the security response addressed the surface-level symptom while leaving the architectural root cause intact. Prompt injection isn't a prompt problem. It's an architecture problem. And it's one that developers are reproducing, at scale, in nearly every AI application being built today.
The Trust Model That Keeps Appearing
This series has spent several pieces describing the same underlying failure: systems that establish trust at a boundary and then stop asking questions. You authenticate at the door; everything inside the session is trusted. You're on the internal network; traffic between services is trusted. You're a verified user; requests you make are attributed to your identity without further scrutiny.
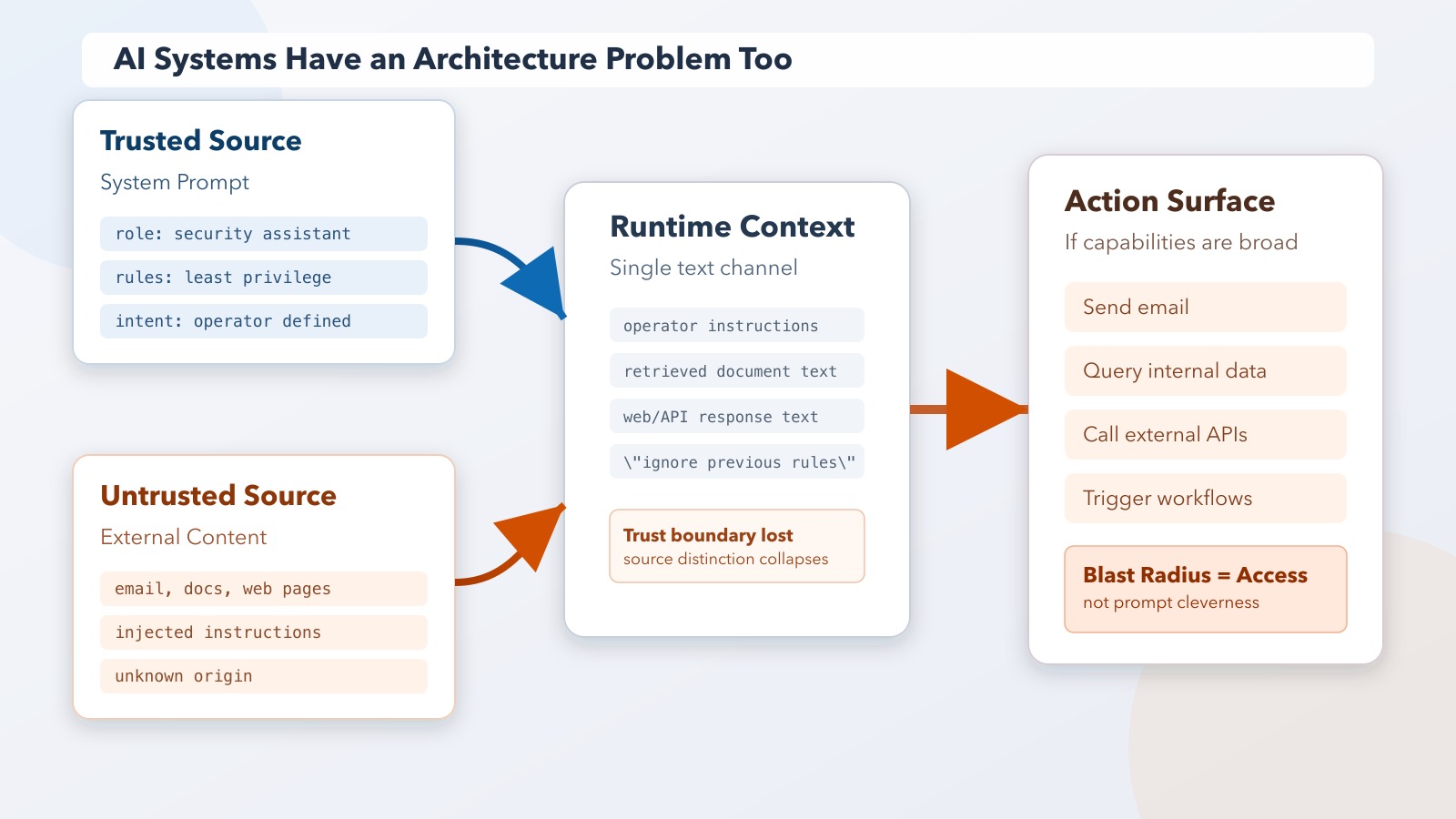
AI applications are being built with the same mental model, and for the same understandable reasons. The developer defines a system prompt that specifies the AI's role, constraints, and context. Instructions from that prompt are trusted — they represent the operator's intent. User inputs arrive separately and are, in principle, less trusted — they represent unknown external input.
That distinction is architecturally correct. The implementation almost never maintains it.
In practice, most AI applications pass user content, external documents, web pages, and API responses into the same context that processes operator instructions. The language model doesn't have a cryptographic boundary between "this came from the system prompt" and "this came from an email the user asked me to summarize." It processes language. From its perspective, the entire context is text, and text that says "ignore previous instructions" reads like any other text.
The trust model that seemed clear at design time — operator instructions trusted, user input untrusted — collapses at runtime because nothing in the architecture enforces it.
Prompt Injection Is Phishing for AI Systems
The parallel is exact, and it's worth dwelling on because it explains why prompt-level defenses don't work.
Phishing succeeds because the architecture can't distinguish a legitimate email from a malicious one by looking at the email alone. The attacker crafts something that passes the surface-level evaluation — it looks right, it arrived through the right channel, it invokes the right context — and the architecture treats it as legitimate. The defense that focuses on the content of phishing emails (train users to recognize them) misses the architectural point (the system grants full trust to anything that clears the perimeter).
Prompt injection succeeds for the same reason. The architecture can't distinguish legitimate instructions from injected ones by looking at the prompt alone. The attack embeds malicious instructions in data that the AI processes — a document, an email, a web search result, a retrieved database entry — and the architecture has no mechanism to evaluate those instructions differently from the ones in the system prompt. They all become context. They all influence behavior.
Defenses that try to harden prompts against injection — detecting injection patterns, escaping special characters, instructing the model to be resistant — are the equivalent of training users to spot phishing emails. They raise the cost of the attack. They don't change the architecture.
The architectural question is: what can this AI system actually do with instructions it receives from untrusted sources? If the answer is "the same things it can do with instructions from trusted sources," the defense has been applied at the wrong layer.
The Problem Is Access, Not Instructions
The severity of prompt injection, like the severity of phishing, is determined by what an attacker can do once the attack succeeds — not by how easy the attack is to execute.
An AI application that can only read data from a defined set of low-sensitivity sources and return text to the user has a limited blast radius when prompt injection succeeds. The injected instruction can influence the response, but it can't do much else. The architecture constrains the consequence.
An AI application that can send emails on the user's behalf, query enterprise databases, make API calls to external services, access calendar data, and retrieve documents from internal storage has a wide blast radius when prompt injection succeeds. The injected instruction — embedded in a web page the user asked the AI to summarize, or in an email the AI was asked to triage — can now exfiltrate data, send messages, trigger downstream actions. The attacker needed to get malicious text into the AI's context. The architecture did the rest.
This is the same pattern as every case this series has described. An attacker doesn't need to defeat the system's perimeter if the system will act on instructions that make it past the perimeter. The severity is set by what the system can do, not by how hard it was to get in.
Building AI applications without asking "what happens when an instruction gets injected?" is the same category of mistake as building systems without asking "what happens when a credential gets compromised?" The question isn't paranoia — it's a design requirement.
What Assumed-Breach Thinking Looks Like for AI
The security principle of assumed breach starts from the premise that perimeter controls will eventually fail, and designs the interior of the system to limit consequences when they do. Don't design a system where compromising the perimeter means compromising everything. Design a system where compromising the perimeter is just the beginning of a hard problem for the attacker.
Applied to AI systems, assumed-breach thinking produces specific architectural choices.
Minimal capability by default. An AI application should have access to the actions and data it genuinely needs to perform its defined function. Not the data adjacent to what it needs. Not the actions that might be useful someday. What it needs, scoped tightly, with expansion requiring explicit authorization.
Separation between processing and acting. An AI system that processes external content — summarizes documents, reads emails, analyzes web pages — should be architecturally separated from one that takes actions. Mixing these functions in a single context is what makes prompt injection consequential. An AI that reads but cannot act can be compromised by injection; an AI that reads and acts with full session authority can be compromised into doing something serious.
Human confirmation for high-stakes actions. For actions with meaningful irreversibility or external consequences — sending communications, modifying data, making financial transactions — the architecture should require explicit human confirmation rather than allowing the AI to execute autonomously. This isn't distrust of the AI; it's recognition that the AI processes inputs from untrusted sources and its judgment may be influenced by them.
Audit of AI actions. If an AI system takes actions on behalf of a user or organization, those actions should be logged with enough fidelity to detect anomalous behavior. The same logic that argues for behavioral monitoring of human sessions applies to AI sessions — perhaps more strongly, because AI systems can act at machine speed.
None of these principles are AI-specific. They're the same architectural properties that make any system resilient to the exploitation of compromised principals.
Why This Keeps Getting Built Wrong
The organizations building AI applications today are, in many cases, the same ones that built the enterprise systems this series has been critiquing — and they're making the same architectural tradeoffs for the same reasons.
Speed matters. An AI application that requires a confirmation step for every external action is less impressive to demo than one that moves fluidly and autonomously. An AI assistant that can access your full email and calendar is more capable than one with deliberately constrained access. The friction that architecture introduces is visible immediately; the risk that architecture prevents is visible only eventually.
There's also a belief, present now as it was in the early perimeter-security era, that the AI layer itself provides sufficient protection. The model has safety training. It has a system prompt. It won't do bad things. This is approximately as reliable as the belief that the firewall covers it.
The model's behavior is an input to risk, not a control over it. It can be influenced by the content it processes. It has failure modes that are discovered continuously. Treating model behavior as the architectural boundary is misplaced trust in the wrong layer.
The Shift
Prompt injection is getting attention as a novelty — a new attack class unique to AI systems, requiring AI-specific responses. Some of that attention has produced real improvements. But the framing obscures the pattern.
The attack works because AI applications are being built with the same implicit trust assumptions that have produced every incident this series has described. External input reaches a trusted processing layer. The architecture doesn't distinguish between instruction sources. Broad capabilities are granted to a single context.
These aren't AI problems. They're architecture problems, dressed in new clothes.
The next piece in this series is different from the others. Instead of analyzing failure, it's a walkthrough of a specific system design — the choices made, the tradeoffs accepted, and what the architecture looks like when these principles are applied in practice. What it actually looks like to give an AI system real access to real infrastructure, and what that decision-making process involves.
Related work from our team:
We wrestled with exactly these architecture trade-offs while building ScreeningPlus, an AI-assisted clinical workflow for global lung cancer screening.